Code
Code
 Paper
Paper
Abstract
We introduce AnywhereVLA, a modular pipeline designed to perform mobile manipulation in large-scale novel dynamic indoor environments with just one language command. Our system combines Vision-Language-Action (VLA) manipulation capabilities with active environment exploration, enabling robots to navigate and manipulate objects in previously unseen environments. By leveraging a purpose-built pick-and-place dataset and 3D point cloud semantic mapping, AnywhereVLA exhibits robust generalization capacities across diverse indoor scenarios. The modular architecture allows for seamless integration of exploration and manipulation tasks, making it suitable for real-world applications in dynamic environments.
Method
AnywhereVLA takes a natural language command as input and simultaneously performs environment exploration while executing mobile manipulation tasks. Our system integrates several key components: (1) Command Interpreter that parses complex tasks into simpler actions, (2) Object Perception module using YOLO v12m for object detection and 2D-to-3D projection for semantic mapping, (3) Active Exploration system that guides navigation in unknown environments, and (4) VLA Manipulation module for precise object interaction. The system leverages 3D point cloud semantic mapping to maintain spatial understanding and enables robust generalization across diverse indoor scenarios.
System Architecture
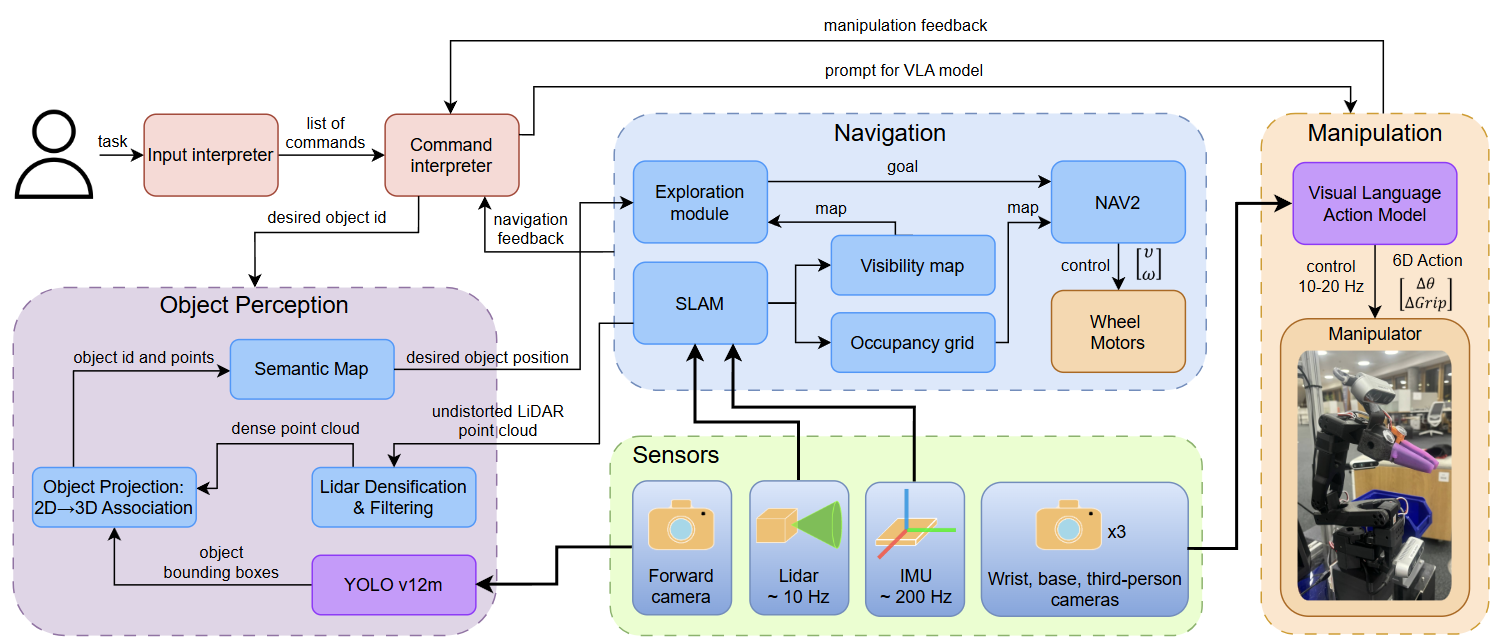
Active SLAM & Autonomous Exploration
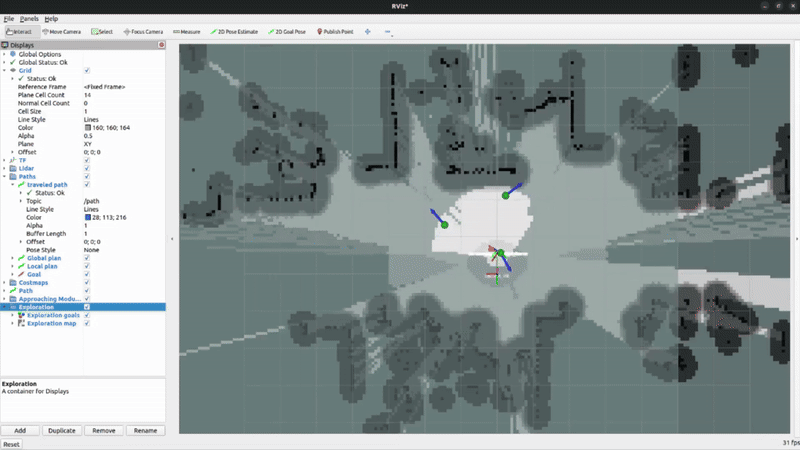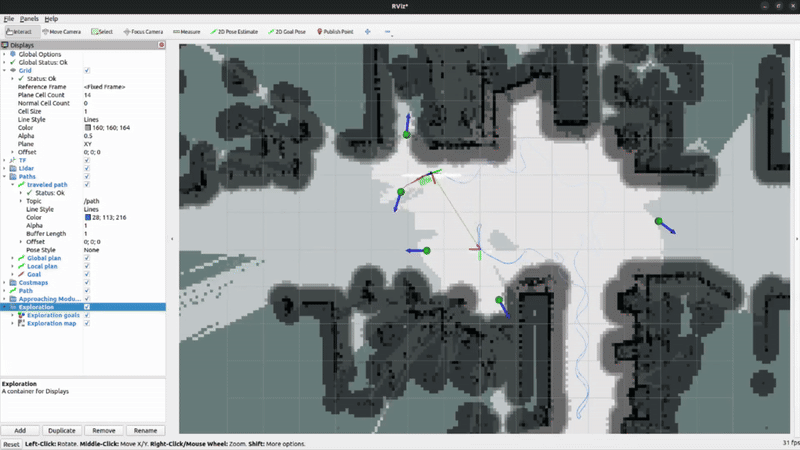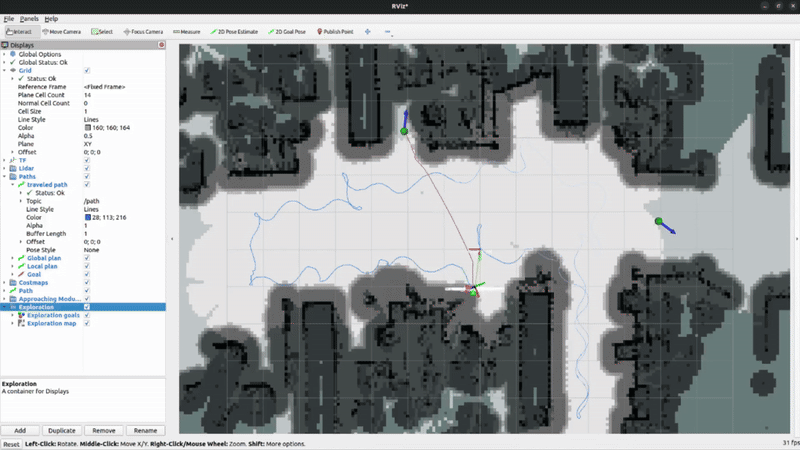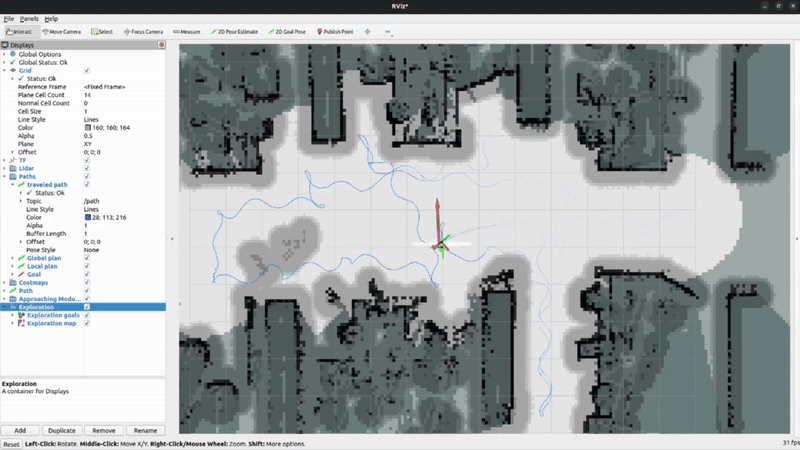
System Demonstrations



Applications